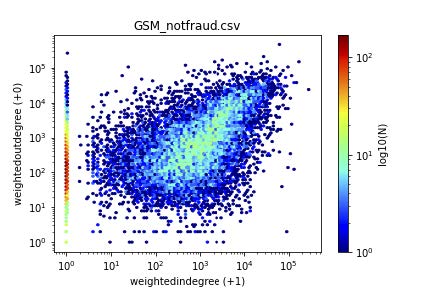
Fraud detection, micro-clusters and scatterplots Acknowledgements The results and analysis presented here were done with contributions from Mirela Cazzolato (USP, and CMU), Saranya Vijayakumar (CMU), Xinyi (Carol) Zheng (CMU), Meng-Chieh (Jeremy) Lee (CMU), Namyong Park (CMU), Pedro Fidalgo (Mobileum), Bruno Lages (Mobileum), and Agma Traina (USP). Reminders – Problem definition and past insights As we mentioned in the February 2022 blog post, the problem we are focusing on is to spot fraudulent behavior in a who-calls-whom-and-when graph. We distinguished between the supervised case (where we are given a list of fraudulent subscribers (labeled data)), and the un-supervised one, where […]
Read More
AIDA paper presents a mechanism that ensures better performance and reduces costs in IoT devices “Adaptive Database Synchronization for an Online Analytical Cloud-to-Edge Continuum” is the new paper of the AIDA project, which was presented this week at the ACM Dependable, Adaptive, and Secure Distributed Systems (DADS 2022). Internet of Things devices are generally underpowered, but they exist in large volumes and are located very close to where the data is captured. The use of these devices is increasingly common in the industry, agriculture, running cities, and even at homes. Because of their limitations, the data is traditionally transferred periodically to […]
Read More
Federated Machine Learning Federated Learning (FL) is a collaboratively decentralized privacy-preserving technology to overcome the challenges of data storage and data sensibility [1]. The last few years have been strongly marked by artificial intelligence, machine learning, smart devices, and deep learning. As a result, two challenges arose in data science, impacting how data can be accessed and used. First, with the creation of the General Data Protection Regulation (GDPR) [2], the data became protected by the regulation. Institutions cannot store or share data without users’ authorization. Another challenge is that in the era of big data, a large volume of […]
Read More
Finding Anomalies in Large Scale Graphs Problem definition Given a large, who-calls-whom graph, how can we nd anomalies and fraud? How can we explain the results of our algorithms? This is exactly the focus of this project. We distinguish two settings: static graphs (no timestamps), and time-evolving graphs (with timestamps for each phone). We further subdivide into two sub-cases each: supervised, and unsupervised. In the supervised case, we have the labels for some of the nodes (‘fraud’/’honest’), while in the unsupervised one, we have no labels at all. Major lessons For the supervised case, the natural assumption is that […]
Read More
A Data Management Architecture for AIDA One of the major challenges in the evolution of the RAID platform during the AIDA project is the need to further distribute the platform components to achieve greater levels of scalability, by leveraging the increasing edge computing capacity made available by the IoT and the imminent large-scale deployment of 5G cellular technology. The advent of 5G networks and growing adoption of Internet of Things (IoT) devices lead to more opportunities for data collection and processing with hybrid edge-cloud systems. In this architecture, edge devices — placed near where the data is being […]
Read More