One of the major challenges in the evolution of the RAID platform during the AIDA project is the need to further distribute the platform components to achieve greater levels of scalability, by leveraging the increasing edge computing capacity made available by the IoT and the imminent large-scale deployment of 5G cellular technology.
The advent of 5G networks and growing adoption of Internet of Things (IoT) devices lead to more opportunities for data collection and processing with hybrid edge-cloud systems.
In this architecture, edge devices — placed near where the data is being collected/accessed — execute some of the processing while offloading other more complex work to the cloud, which is scalable on demand. However, edge-cloud architectures present several challenges when it comes to data management. Most of the difficulties are due to their inherently large-scale, distributed, and heterogeneous deployments, namely:
- Replicating stateful (edge or otherwise) components for scalability requires synchronization, which can be expensive and makes fault tolerance more complex;
- Large-scale data replication between the edge and the cloud raises issues in terms of network latency and storage capacity;
- The heterogeneity of edge devices, namely in the context of IoT, encounters a very diverse set of data models, which requires data processing frameworks to handle each one on a case-by-case approach.
For example, in the network of edge-cloud services, such as firewalls and load balancers, there has been a shift to virtualizing functions to cut operation and management costs and increase elasticity. However, Virtual Network Functions (VNFs) that store data often rely on two techniques: use the operating system level memory sharing techniques for scalability or delegate data management to a standalone centralized database. The former helps to reduce the latency but fault-tolerance is harder to achieve and it limits all VNFs replicas to the same virtual machine. The latter improves scalability and fault-tolerance but increases latency. Although some solutions rely on eventual consistency to improve both scalability and latency, it is not enough for functions that require strong consistency or present non-deterministic behavior. However, this can be circumvented with expensive distributed locking.
On the other hand, the system must answer analytical queries on data collected in the edge. For example, it must be capable of efficiently answering ad-hoc queries for exploratory data analysis. One of the main challenges of this workload is that fetched data is unpredictable. Therefore, the system must be able to adapt to different workloads, by achieving an optimal tradeoff between the network and the computing power of the edge. In an environment with a substantial number of IoT devices, sending all collected data to the cloud consumes network and CPU resources on the edge, which is often limited due to cost and energy factors. Additionally, it introduces delays to the data that is actually needed at the moment. Finally, the heterogeneity of the devices and the collected data makes it difficult for the cloud to have a consistent and holistic view of data, increasing the complexity of analytical workloads.
The edge computing paradigm aims at leveraging the computational and storage capabilities of edge devices while resorting to cloud computing services for more demanding processing tasks that cannot be done at the edge. Edge devices generate large volumes of data that may need to be transferred to the cloud and that come from several types of data sources. Therefore, we propose the AIDA-DB unified data management architecture for an edge and cloud continuum, summarized in Fig. 1, that is able to tackle both analytical and transactional workloads, both relying on a polyglot middleware.
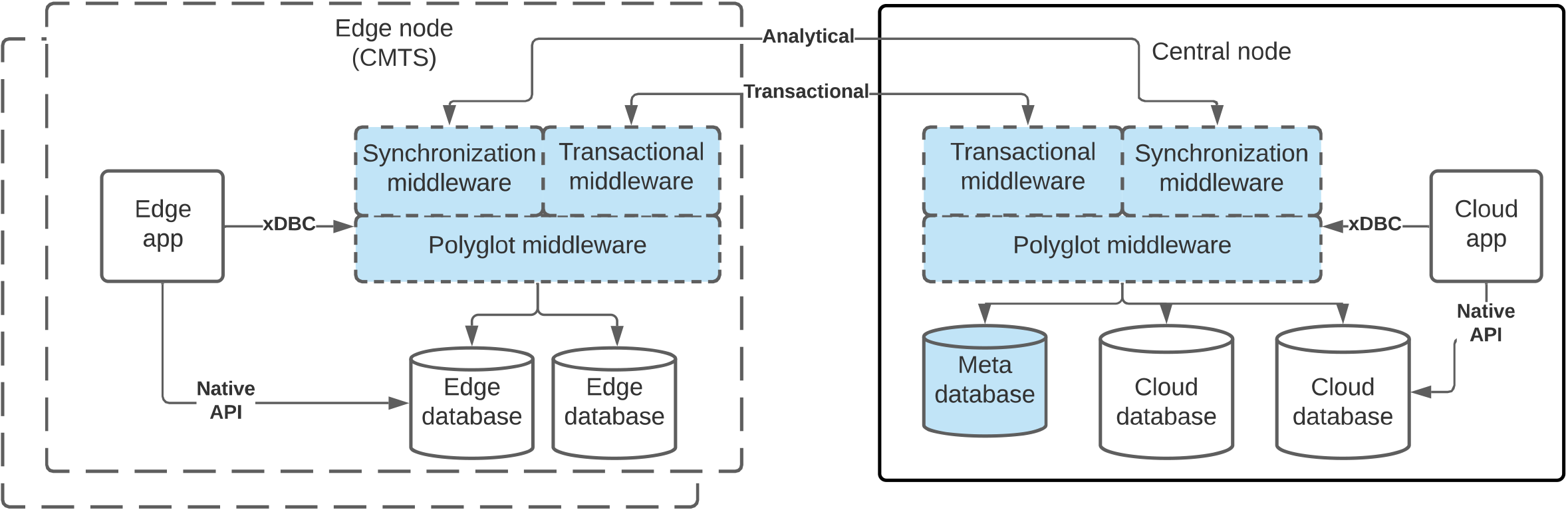
AIDA-DB unified data management architecture for an edge and cloud continuum
In detail, the polyglot middleware processes data from different sources, which have different formats and encodings. This component is capable of efficiently performing queries over an integrated view of the data, by exploiting the underlying edge’s query engines.
The synchronization middleware is in charge of efficiently transferring data from the edge to the cloud. It does so by considering the data that is currently required by the cloud and the data that is already cached. Then, it synchronizes the missing data based on a balance between the network delay and the impact on the edge resources.
Finally, the transactional middleware guarantees consistent reads and isolated and atomic updates across the edge and cloud continuum.
Our proposal of the AIDA-DB architecture is aimed at enabling emerging complex VNFs and edge-based application services in emerging 5G networks to manage data across a cloud and edge continuum. The key advantages of AIDA-DB which allow this are:
- Global transactional reliability: Managing distributed data across distributed system boundaries and multiple SQL and NoSQL database systems is hard and prone to inefficiencies and errors. By providing a seamless transactional layer, AIDA-DB ensures that business-critical workflows execute across these boundaries and makes edge-based application components and services first-class citizens in complex distributed applications;
- Hybrid transactional-analytical processing: The edge adds an axis of complexity to traditional extract, transform, and load (ETL) procedures, as data needs to be copied across the network to a centralized data warehouse. In contrast, a key driver for the adoption of the edge is to make use of fresher data in applications and services. Therefore, in AIDA-DB we strive for hybrid transactional analytical processing systems that take advantage of cloud elasticity and automatic synchronization to run interactive analytics, such as needed for data exploration, on live or freshly updated data;
- Polyglot processing with a standard API: Although it has become clear that current applications and services need a variety of data management paradigms and tools, this pushes additional complexity into applications and calls for polystores to bridge between them. AIDA-DB innovates by catering for polyglot workloads, across different systems, for both transactional and analytical workloads while exposing all functionality in a standard xDBC interface that accepts polyglot queries;
- Separation of concerns: Abstract management of the cloud and edge divide and support for the SQL query language makes it possible to separate application development concerns — what functionality is needed — from deployment and optimization — how it is provided. This extends to the cloud and edge computing environment the traditional strength of database management systems of providing separate and declarative interfaces for both developers and database administrators (DBAs), making applications reusable and deployable in different contexts. This is particularly suited for platforms as a service (PaaS) as it allows the platform provider to offer managed services.
By INESC TEC