Federated Learning (FL) is a collaboratively decentralized privacy-preserving technology to overcome the challenges of data storage and data sensibility [1]. The last few years have been strongly marked by artificial intelligence, machine learning, smart devices, and deep learning. As a result, two challenges arose in data science, impacting how data can be accessed and used. First, with the creation of the General Data Protection Regulation (GDPR) [2], the data became protected by the regulation. Institutions cannot store or share data without users’ authorization. Another challenge is that in the era of big data, a large volume of data is generated, and it becomes increasingly difficult to store that data in a single location. Therefore, the information is distributed by different servers or generated by smart devices, which creates the need to build models or perform calculations without these data leaving their origin. Thus, a new paradigm emerged, coined as Federated Learning, a sub-area of machine learning that seeks to solve the problem of building distributed models with privacy concerns.
The first work on FL was published in 2017 by McMahan et al. [3]. The authors developed the Federated Averaging (FedAvg) algorithm to improve the recommendation and automatic revision of texts from thousands of users’ devices with the Android mobile system.
Federated Learning falls into three types of architecture based on data distribution among edges in the feature and sample space: horizontal, vertical, and federated transfer learning [4]. An example of these architectures is shown in Figure 1. Horizontal federated learning, also known as sample-based federated learning, is characterized by scenarios where each node holds the same features but different individuals. Vertical Federated Learning or feature-based federated learning is suitable for cases where data is vertically partitioned according to the feature dimension. Unlike the horizontal and vertical architectures, in Federated Transfer Learning (FTL), data shares neither sample nor feature space.
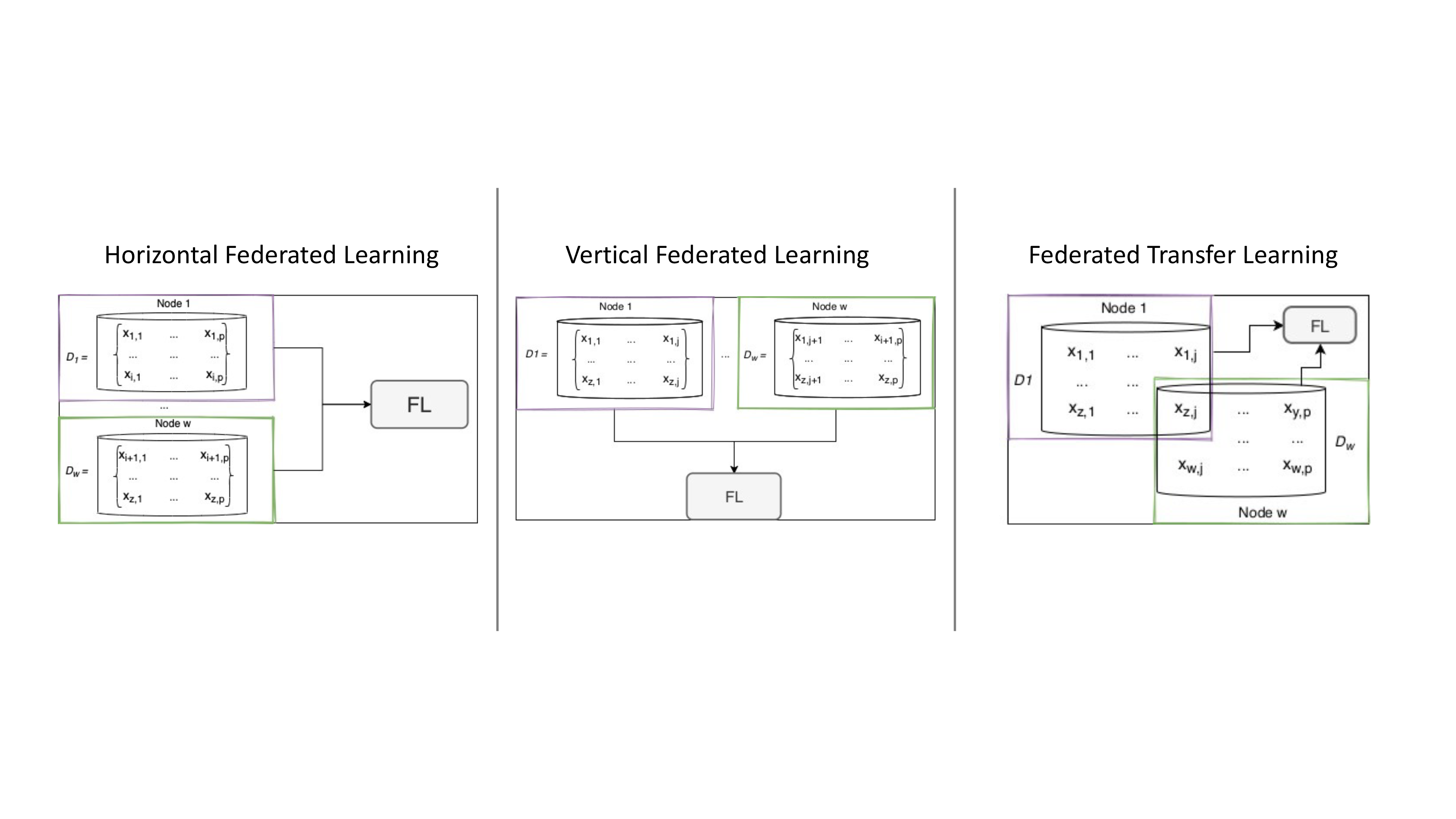
Figure 1 | Federated Learning Architectures
Privacy is often a significant concern in FL. The existing privacy-preserving methods mainly focus on information encryption for the client, secure aggregation at the server side, and security protection for the FL framework. FL’s variety of privacy definitions is classified into global and local privacy [5]. According to Figure 2, the main difference between the two categories is where the privacy-preserving methods are implemented.
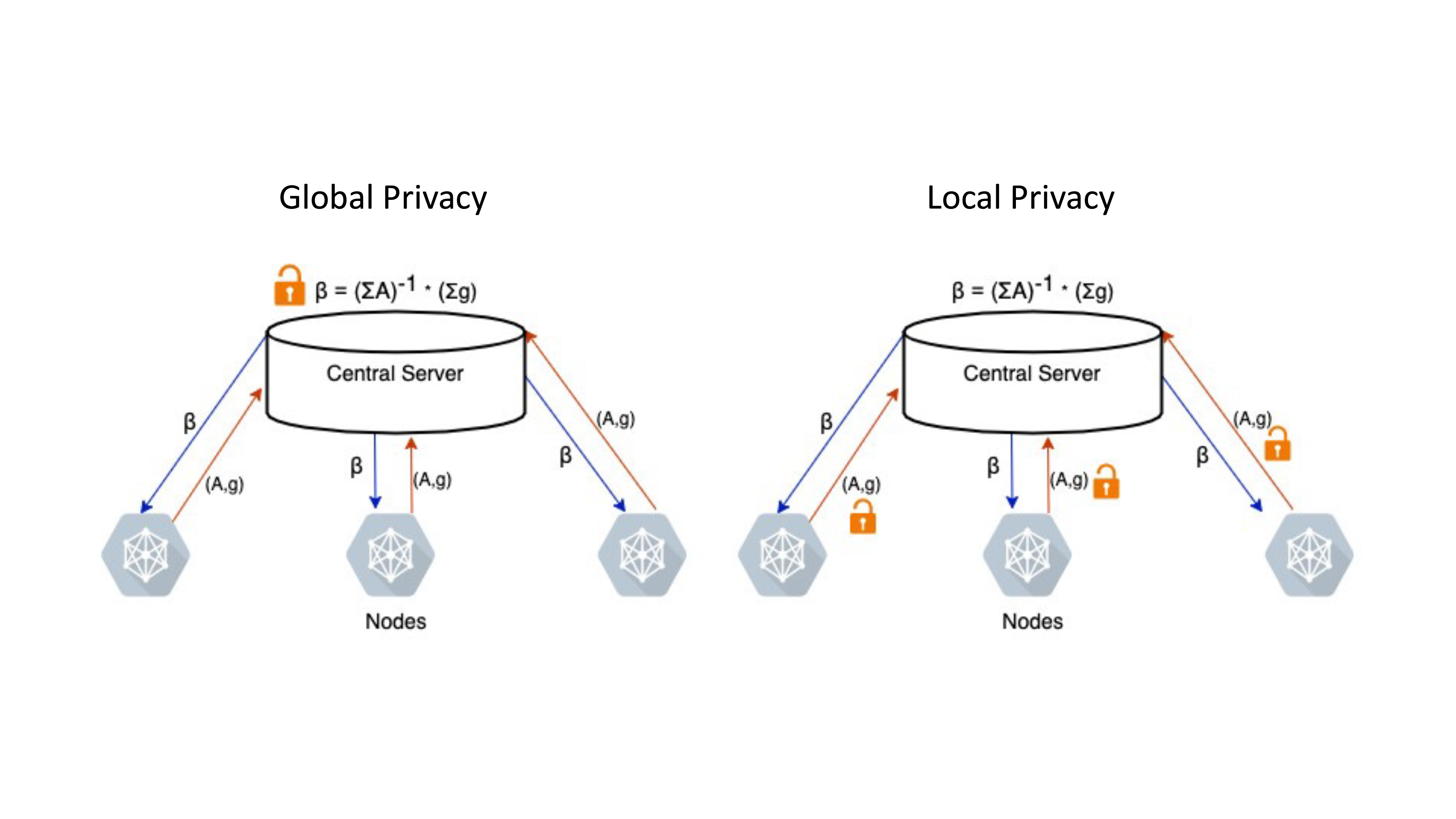
Figure 2 | Categories of Privacy-Preserving Mechanisms (a) Global Privacy (b) Local Privacy
The development of open-source frameworks for FL simulation has the potential to accelerate the research progress. The first framework designed at the production level was TensorFlow Federated (TFF) [6]. The Federated AI Technology Enabler (FATE) is an open-source industrial-level framework [7] built to deal with federated anomaly detection issues such as credit risk control and anti-money laundering.
The evaluation of an FL model consists of accessing the aggregated model after assigning it to each client using the local evaluation datasets. Then, each client shares the performance with the server, which combines local performances in global evaluation metrics. This subject is still in the early stage, and there are open challenges related to the ideal metrics for each type of problem.
This new research area has several open challenges, such as the definition of metrics for model evaluation and communication interoperability and energetic efficiency issues. It is also interesting to research the possibility of adopting white box distributed learning algorithms to promote the models’ explainability, mainly when dealing with interdisciplinary applications. The diversity of applications is still limited to experiments with simulated or traditional machine learning datasets. Several works can deal with horizontally distributed data, but there are still research opportunities to deal with vertical FL and federated transfer learning.
References
[1] Yu, B., Mao, W., Lv, Y., Zhang, C., & Xie, Y. (2022). A survey on federated learning in data mining. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 12(1), e1443.
[2] Voigt, P., & Von dem Bussche, A. (2017). The EU general data protection regulation (gdpr). A Practical Guide, 1st Ed., Cham: Springer International Publishing, 10(3152676), 10-5555.
[3] McMahan, B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017, April). Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics (pp. 1273-1282). PMLR.
[4] Yang, Q., Liu, Y., Chen, T., & Tong, Y. (2019). Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2), 1-19.
[5] Li, T., Sahu, A. K., Talwalkar, A., & Smith, V. (2020). Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine, 37(3), 50-60.
[6] Google. (2020). TensorFlow Federated. https://www.tensorflow.org/federated Accessed 2022.
[7] Webank. (2019). Federated AI Technology Enabler. (FATE). https://github.com/webankfintech/fate Accessed 2022.
By INESC TEC