The evolution of the RAID platform during the AIDA project brings many benefits, but also many security and privacy concerns to be considered. Thus, discovering and implementing measures that address these new risks, while not degrading performance, is of utmost importance. The main challenges are related to the transition to edge, pushing the computational power to the edges of the network, to the integration of 5G supporting multiple tenants and network slicing, and finally to the privacy of the data gathered and analyzed.
Given these changes to the network, communications need to be verified in order to assure that they are secure and that performance isn’t being affected. The network is constantly changing as many devices connect and disconnect from it and have higher and lower traffic, creating the necessity of monitoring the platform to allow a fast response to any change in it. This change in the network creates new potential entry points for attackers to take advantage of or makes it harder to defend attacks that were already possible.
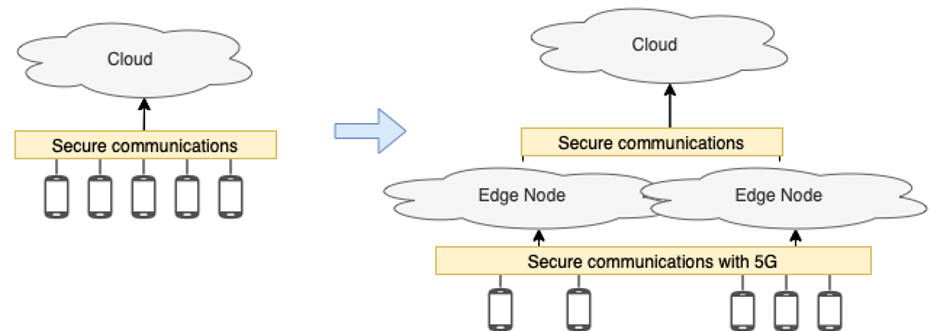
Figure 1: Overview of the changes to the Architecture
Providing Secure Communication among the Components
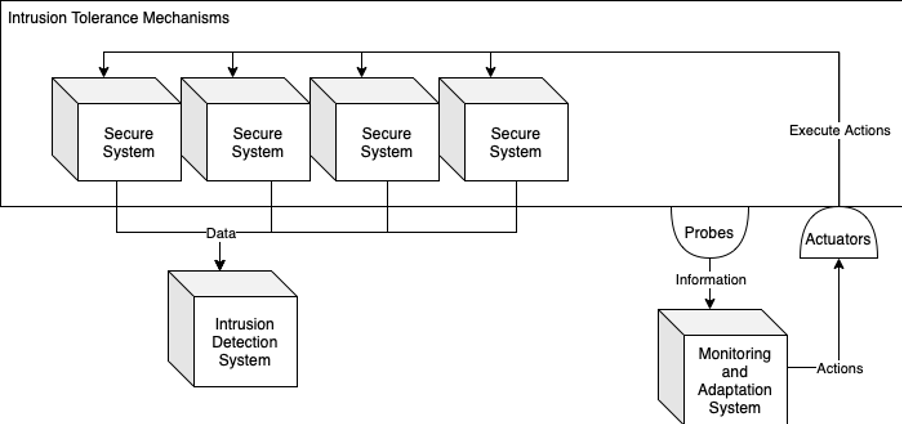
Figure 2: High level perspective of the secure operation of the main software components
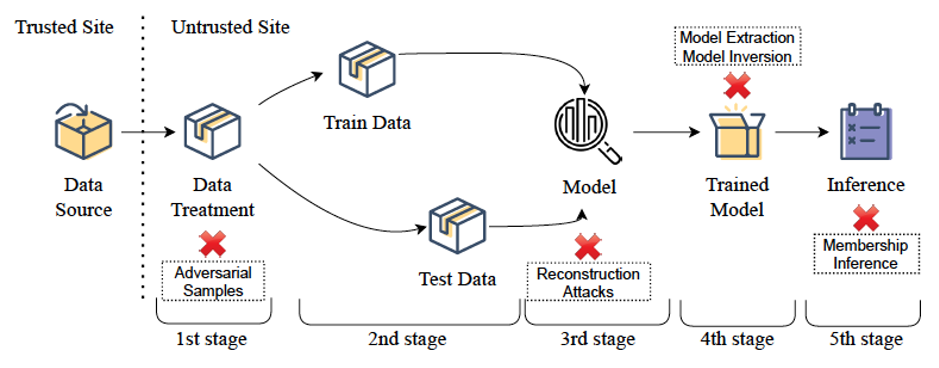
Figure 3: Examples of attacks that can affect ML: Adversarial Samples, Model Extraction, Model Inversion, Reconstruction Attacks, and Membership Inference
Although the use of software-based cryptographic schemes is far from coming to a halt, Trusted Execution Environments (TEEs) are increasingly sought as an alternative solution that can reduce the performance overhead associated with traditional privacy-preserving secure schemes. In AIDA we are exploring this technology to provide a privacy-preserving machine learning solution that can be used in practice, while scaling out for large datasets. SOTERIA is a system for distributed privacy-preserving machine learning, which leverages Apache Spark’s design and its MLlib APIs. Our solution was designed to avoid changing the architecture and processing flow of Apache Spark, keeping its scalability and fault tolerance properties.
Apart from cryptographic mechanisms, privacy guarantees can be provided by applying adequate anonymization mechanisms. However, selecting a privacy-preserving mechanism is quite challenging, not only by the lack of a standardized and universal privacy definition, but also by the need of properly selecting and configuring mechanisms according to the data types and privacy requirements. Moreover, the type of anonymization approaches employed may affect the performance of the machine learning mechanisms considered in the project. Focusing on the data types relevant for the AIDA project, we are developing a privacy framework that allows us to test configurations, apply and assess privacy-preserving mechanisms according to the achieved privacy and utility level of data.
By University of Coimbra and INESC TEC