Handling Update Hotspots in Distributed Database Systems
Motivation
Database systems must deal with the fact that real workloads often exhibit hotspots: Some items at certain times are accessed by concurrent transactions with high probability. This arises in telecoms, sensing, stock trading, shopping, banking, and numerous applications. Some are as simple as counting events, such as user votes or advertisement impressions in Web sites. Some of these applications, such as prepaid telco plans, selling event tickets, or keeping track of remaining inventory, in addition to counting, also need to enforce a bound invariant, that ensures that the quantity being tracked does not cross a set threshold.
Update hotspots mean that locking and validation mechanisms used for isolation have a severe impact on usable throughput. This is particularly challenging in emerging cloud and edge database systems as classical techniques such as escrow locking are not applicable (e.g., locks in MySQL Group Replication are local and transactions in different nodes run optimistically), distributed synchronization has a considerable impact on latency (e.g., waiting for a stable time in Spanner), or the unpredictability makes them ineffective (e.g., how many separate splits are needed in a serverless system). Moreover, in industrial applications, one needs a solution that works in current cloud-based and off-the-shelf systems, that is, using only their application programming interfaces.
MRVs in a Nutshell
Structure
The AIDA project proposes Multi-Record Values (MRVs), a new approach to handle update hotspots in scale-out cloud and edge database systems. It builds on the general strategy of value splitting: To split each contended value into multiple database records, each holding part of the total value, such that they can be accessed concurrently. To add or subtract to the value, one needs to add or subtract to any of these records. To read the current value, one needs to read and sum them all. The main novelty of MRVs is how each transaction is assigned to a physical record and how the various records, holding parts of the total value, are managed efficiently.
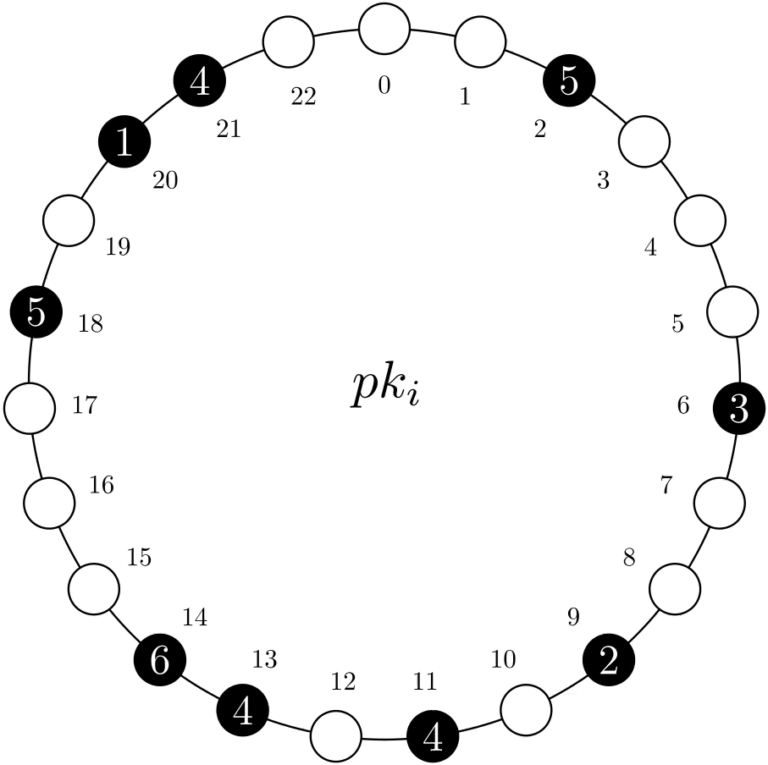
MRVs can be portrayed as a circular structure of size N. Of these N positions, n are assigned to a physical record, which holds a subset of the total value. In the example below, we have an MRV with N=23 and n=9, with the latter represented by black circles.
Figure 1. Representation of MRV pki.
Operations
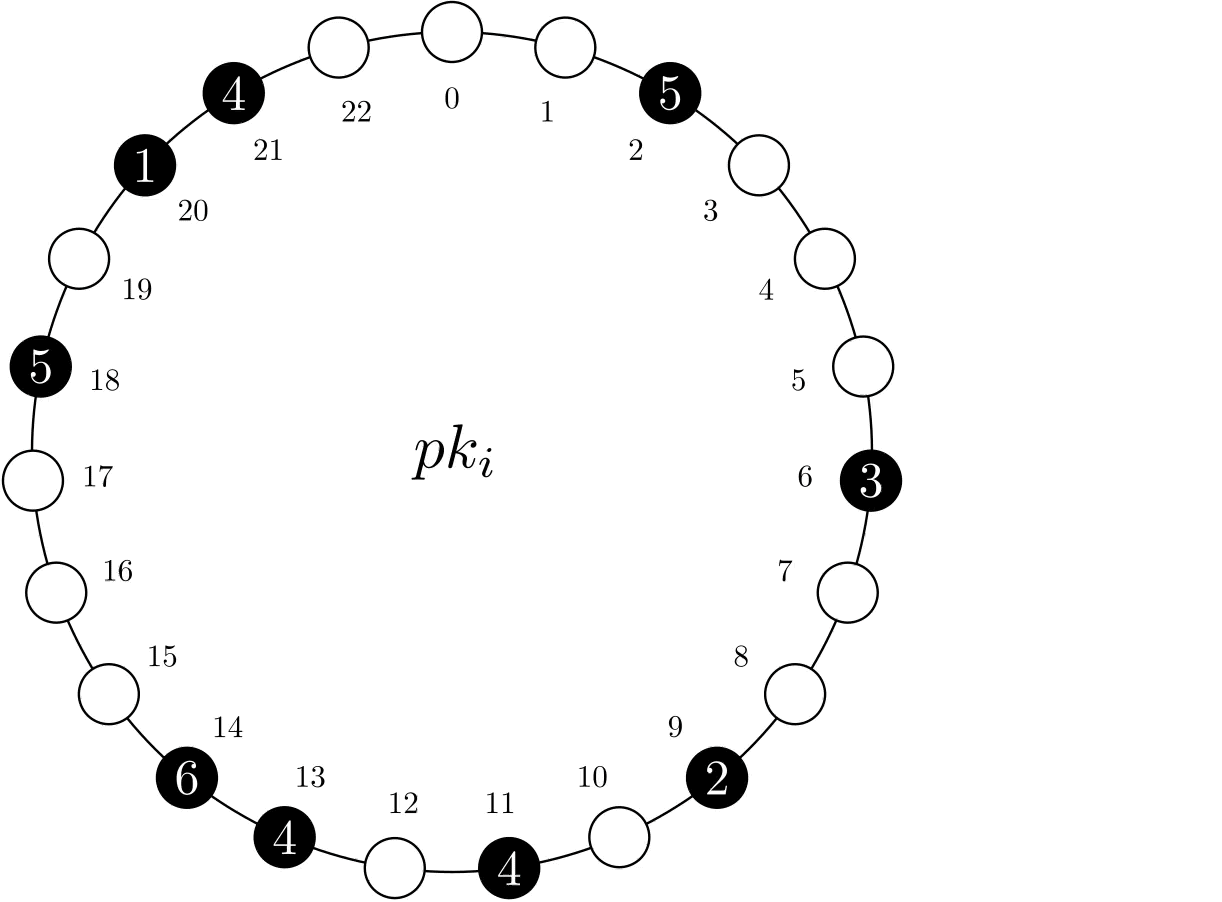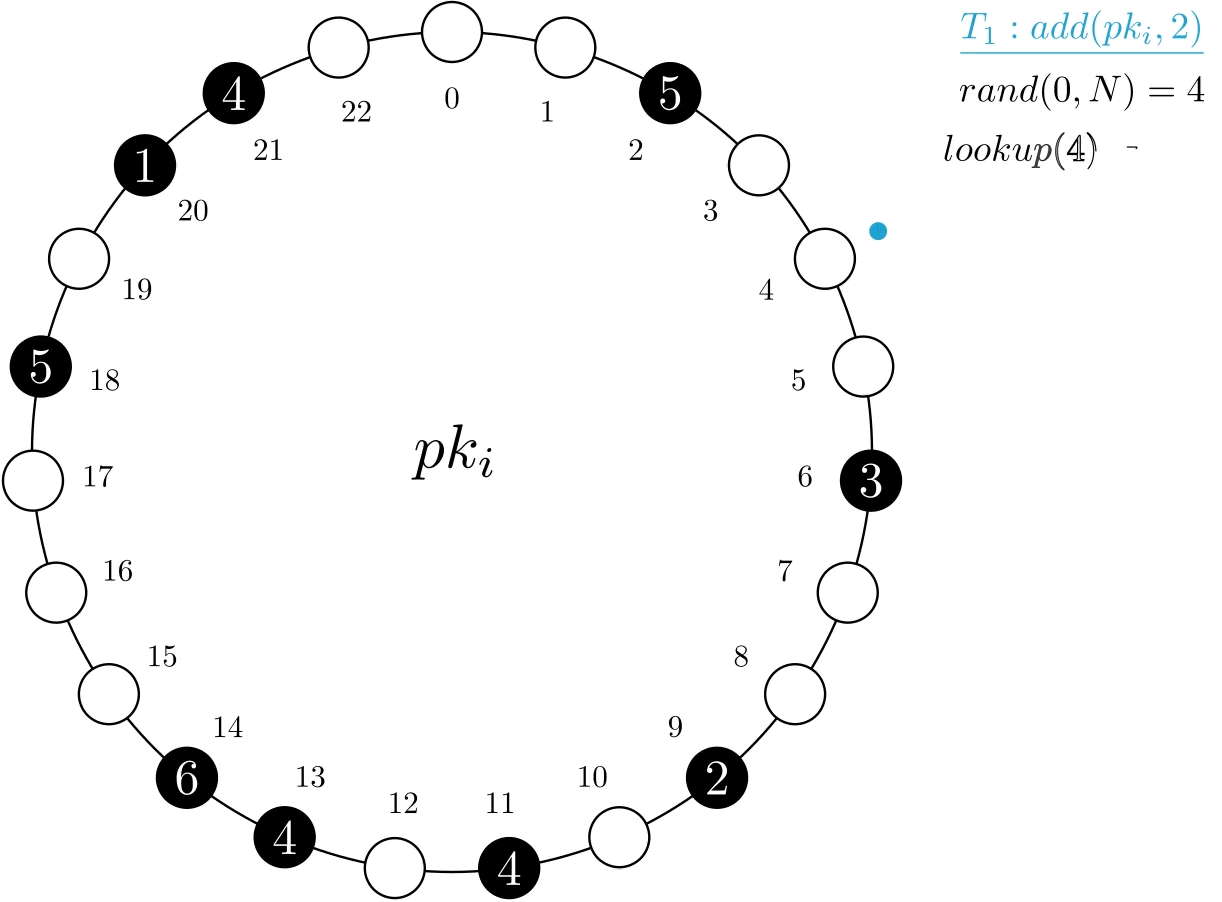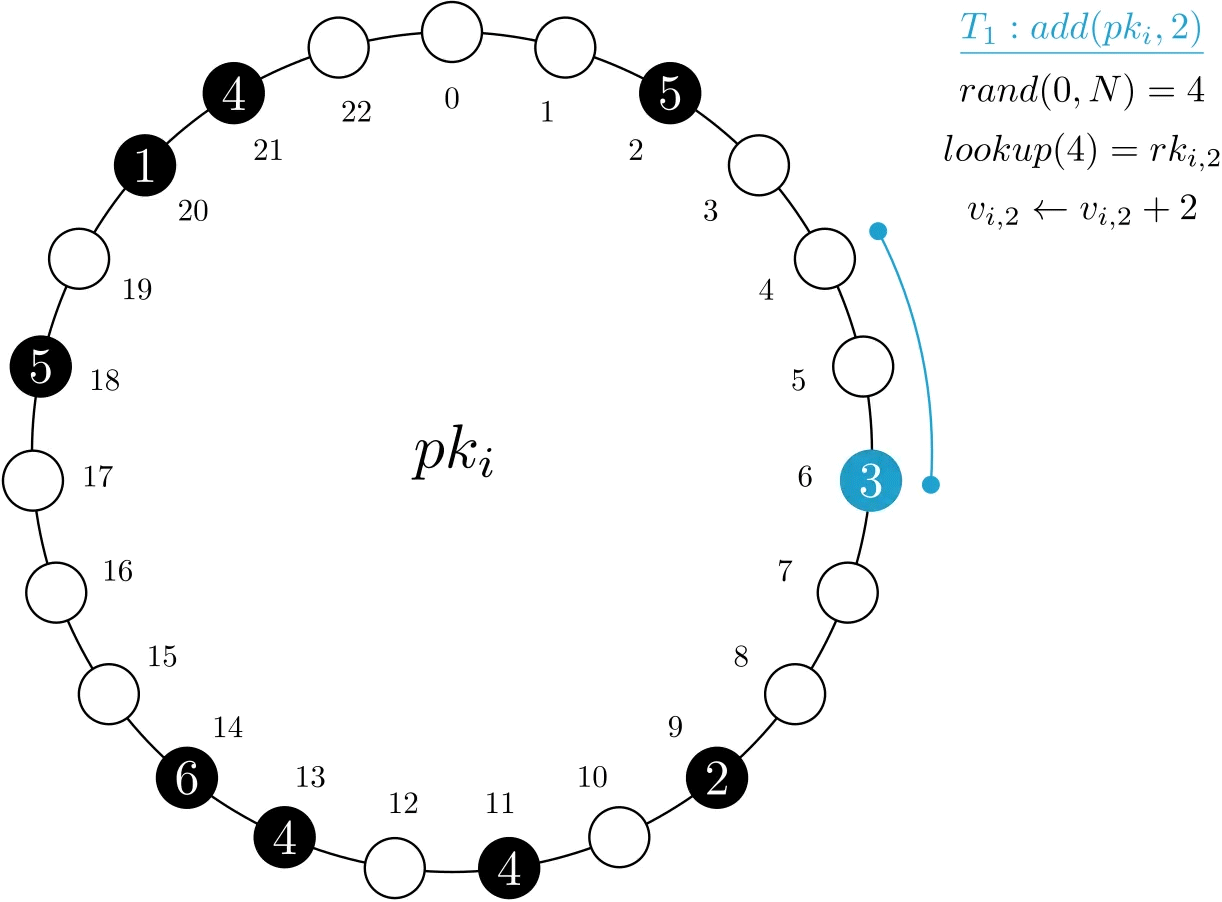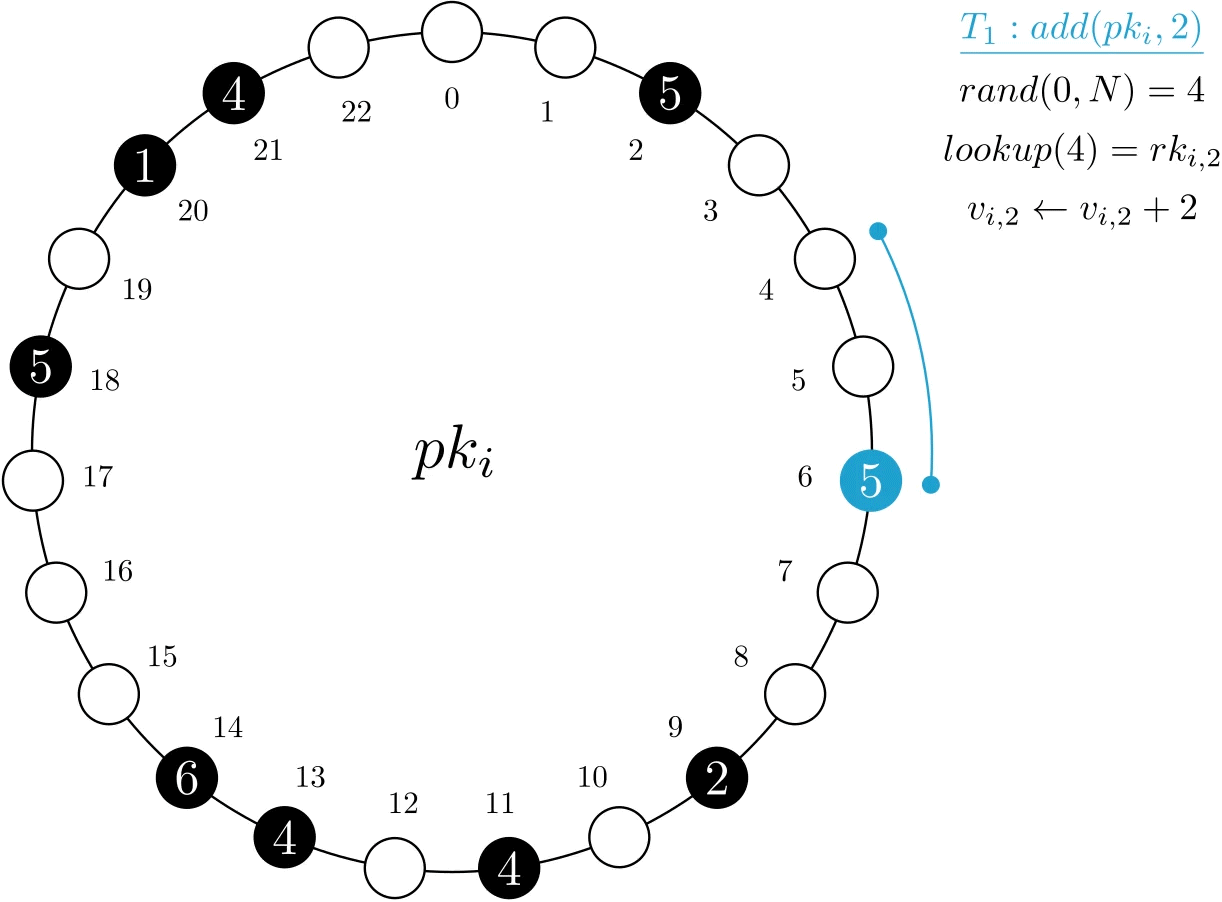
As different clients might have different access patterns, MRVs avoid statically assigning them to records, as done in previous splitting techniques. To ensure that accesses are evenly spread, our first insight in MRVs is to use a random number between 0 and N-1, for each access, to determine which record to use. Assuming that the number of records for each item is big enough, this results in a small probability of conflict. This avoids the need for explicit coordination of clients, which would be costly in a distributed environment.
In the example below, transaction T1 wants to add 2 units to the MRV. As such, it performs a lookup with a random key, 4, and ends up updating the next physical record, assigned at index 6.
Figure 2. Example of a add operation on MRV psi. Only one record is accessed and modified.
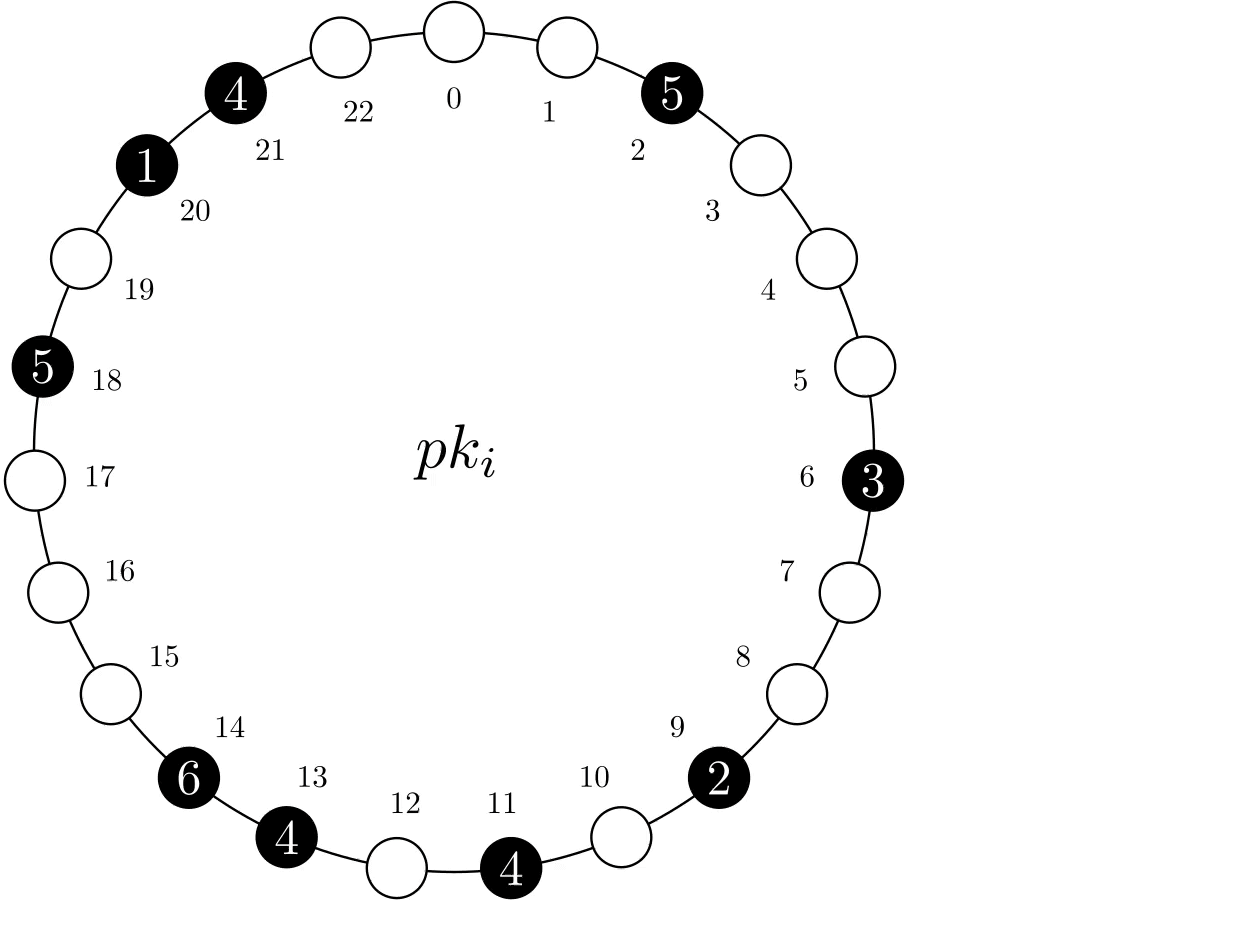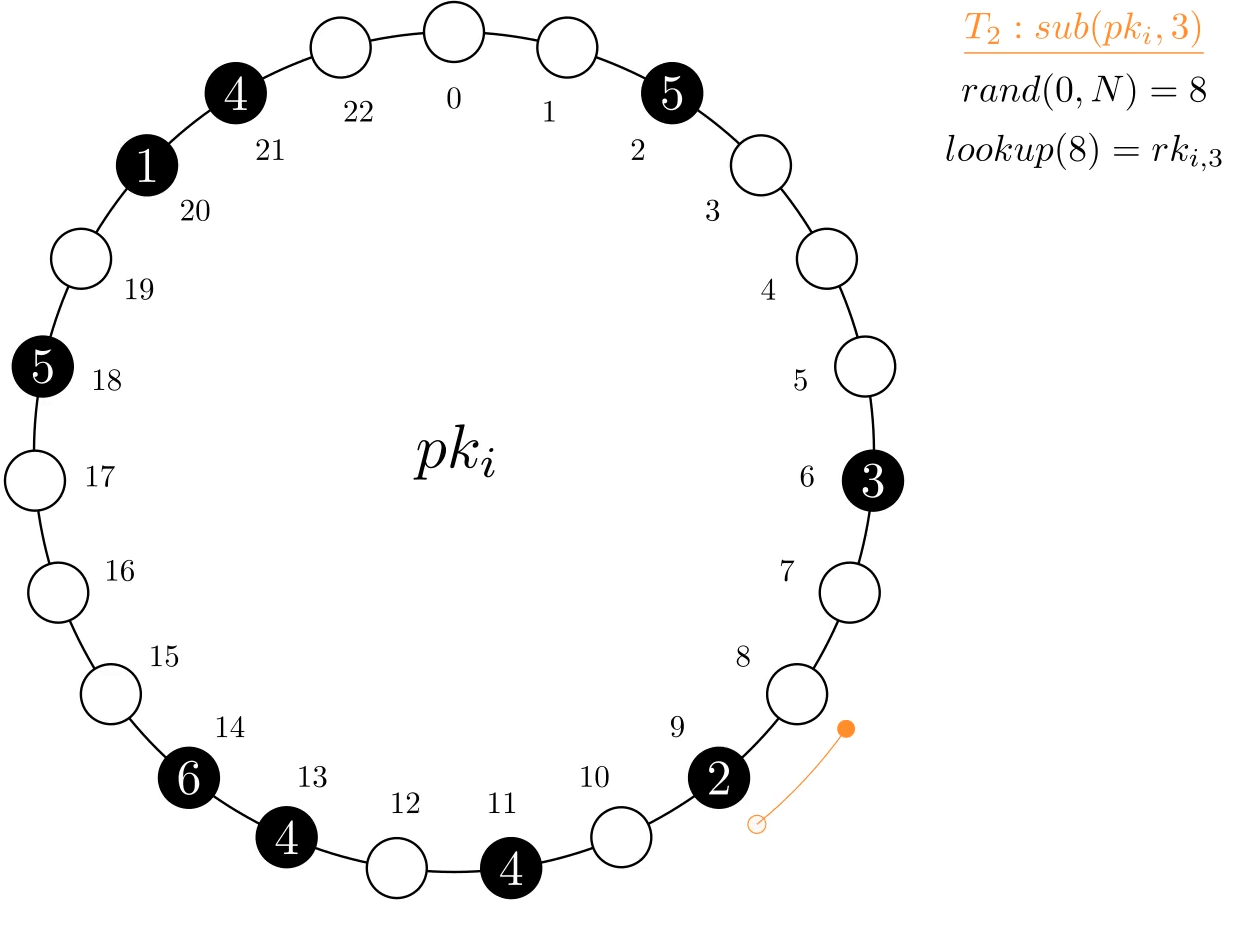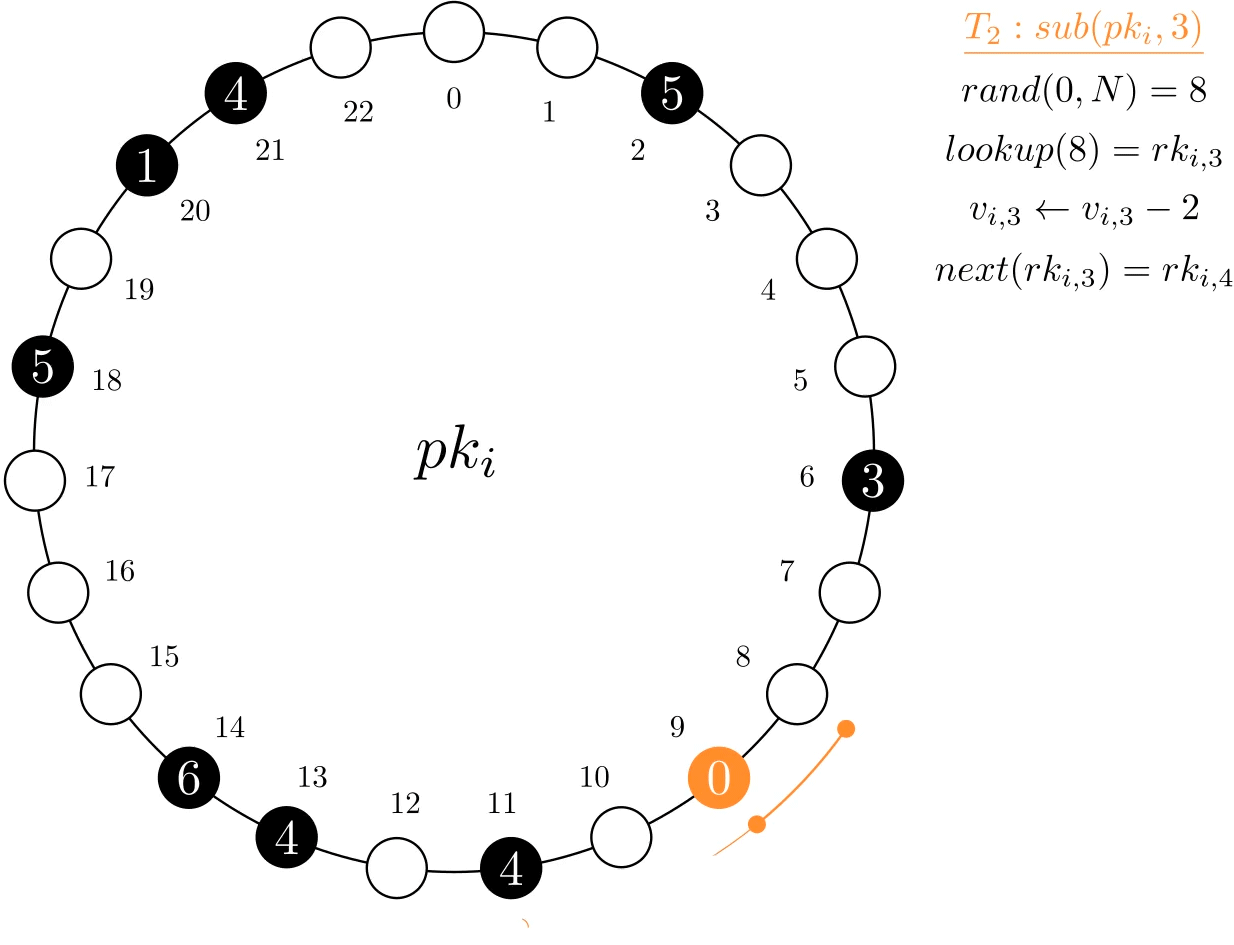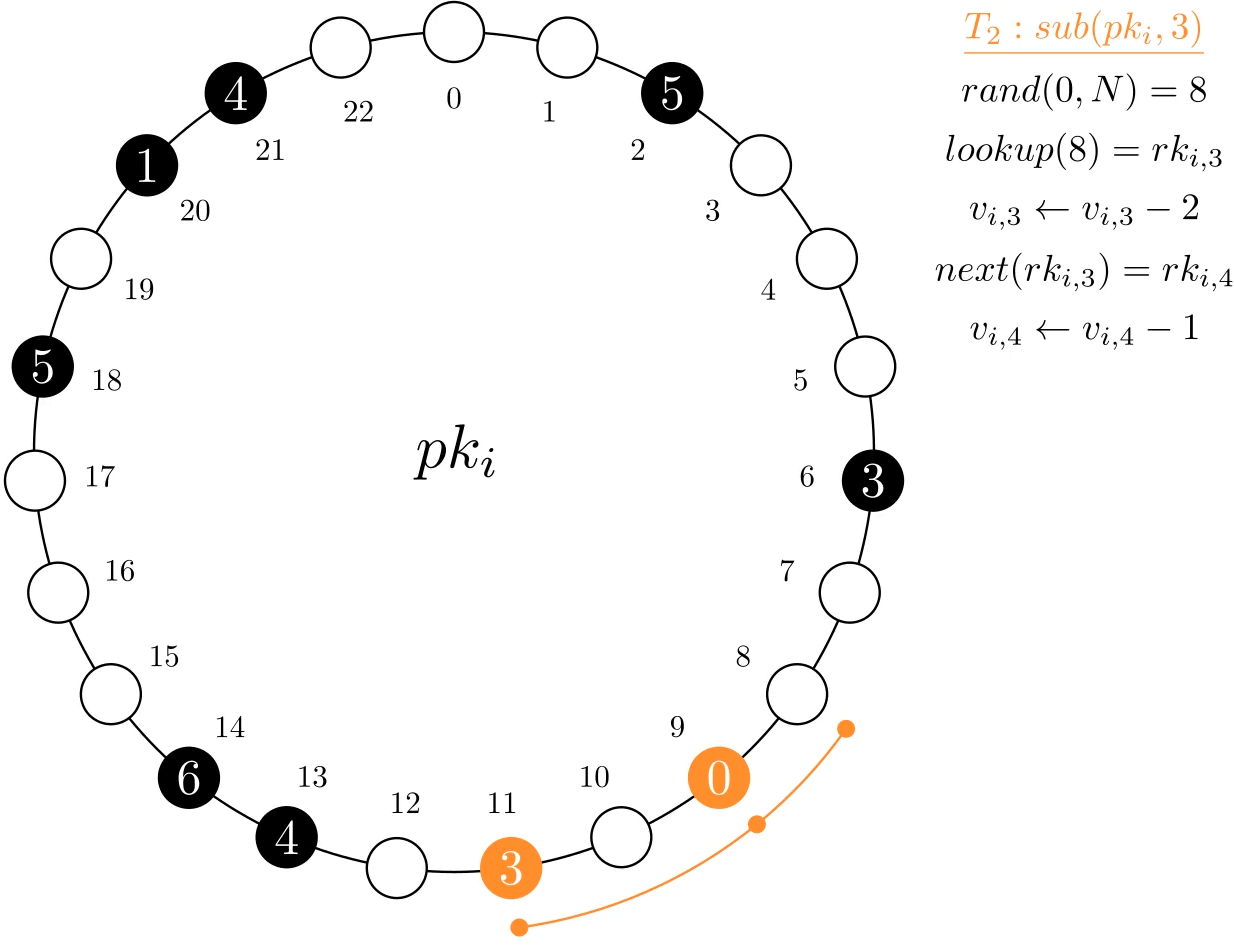
Subtractions might not be fully possible on a single record if its current value is lower than what is being subtracted. Thus, the subtraction might require multiple accesses to complete. This could be done simply by keeping the remainder after a first subtraction and carrying it on to a second random one, and so forth, until it is fully done. This, however, makes it difficult to determine unsuccessful termination, which happens after all records have been visited and there is still a remainder. This is addressed by performing only one random lookup and then scanning to the next record. After the last record, we wrap around and restart the process on the first, hence the circular structure. With a tree-type index, both the lookup and next operations execute efficiently.
If two transactions try to update the same record concurrently, one of those will have to either rollback or wait. MRVs rely on the underlying concurrency control to achieve this task, which means a simplified implementation process.
In the example below, transaction T2 wants to subtract 3 units from the MRV. It first accesses the record at index 8, which only has 2 units. As such, it sets its value to 0 and carries the remainder (1) to the next record.
Figure 3. Example of a sub operation on MRV psi. To complete the operation, two records needed to be accessed and updated.
Adjusting
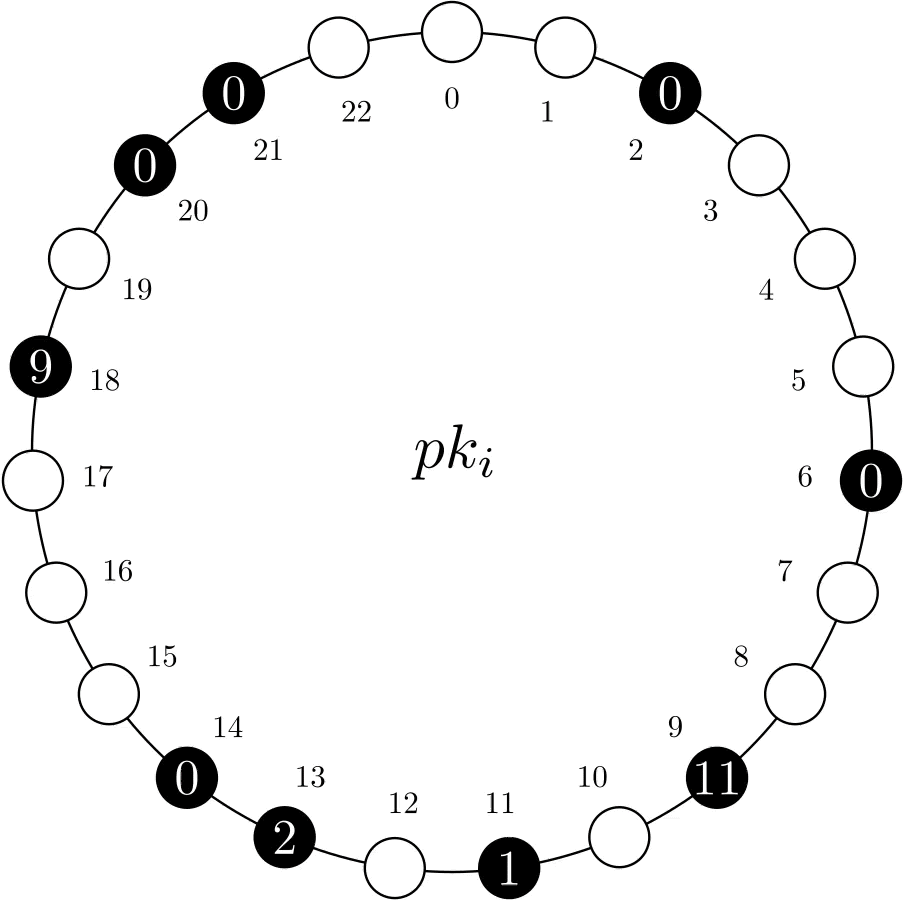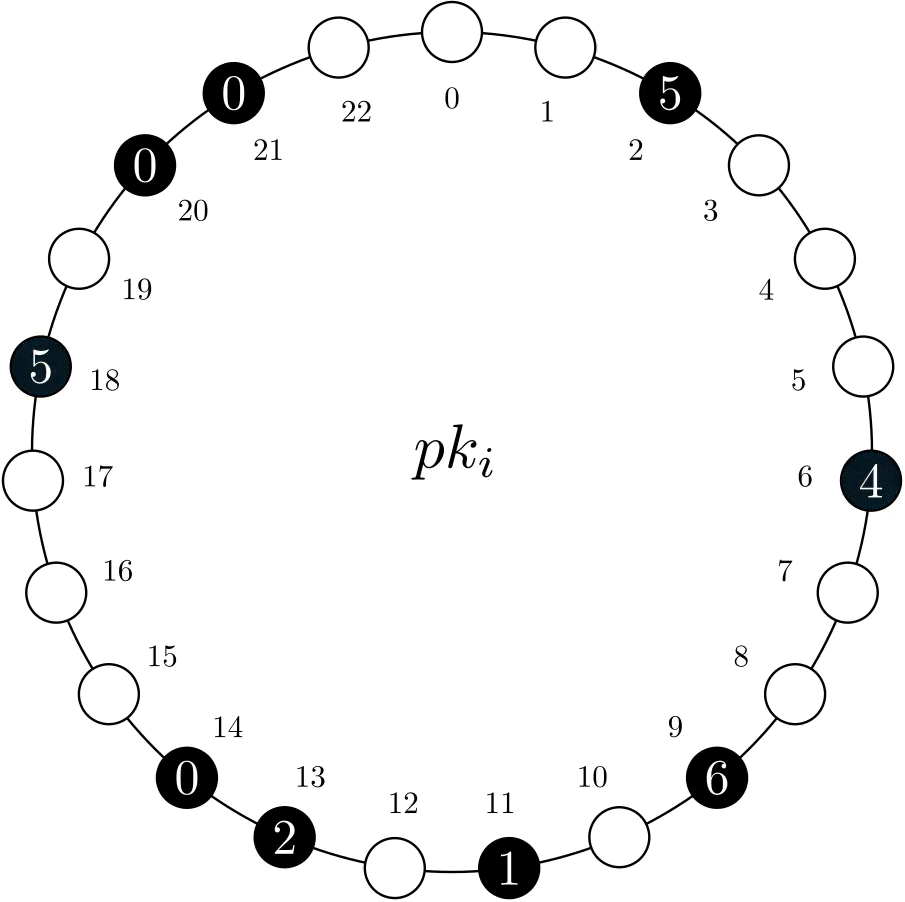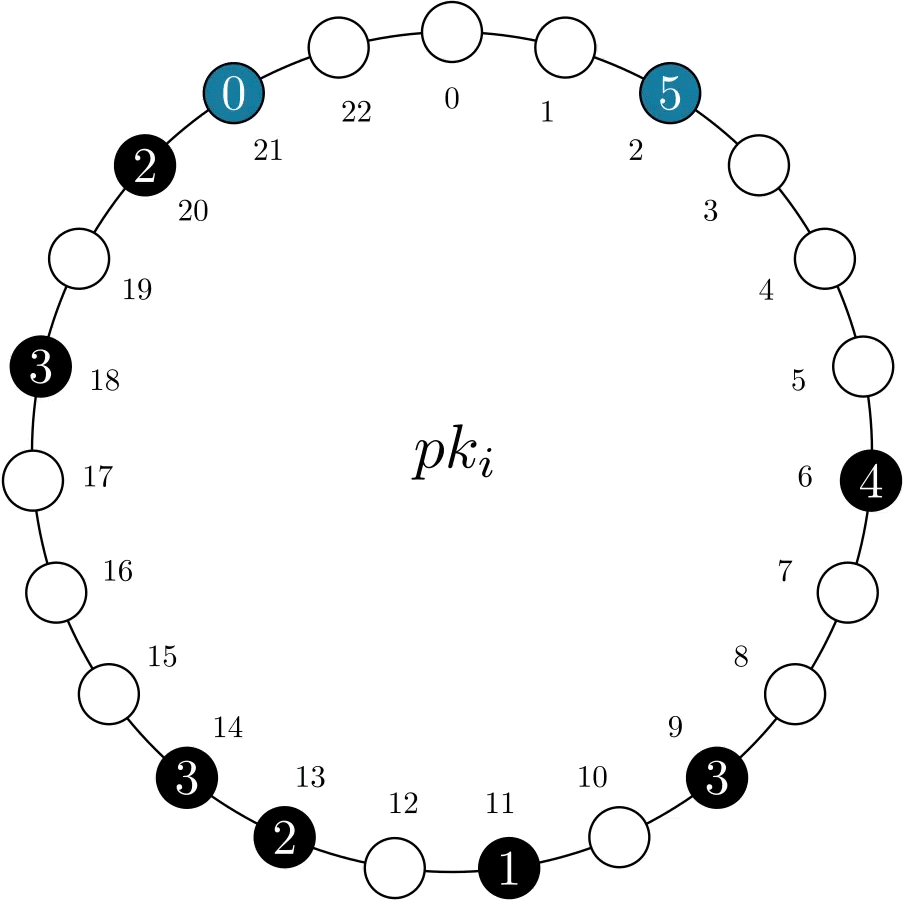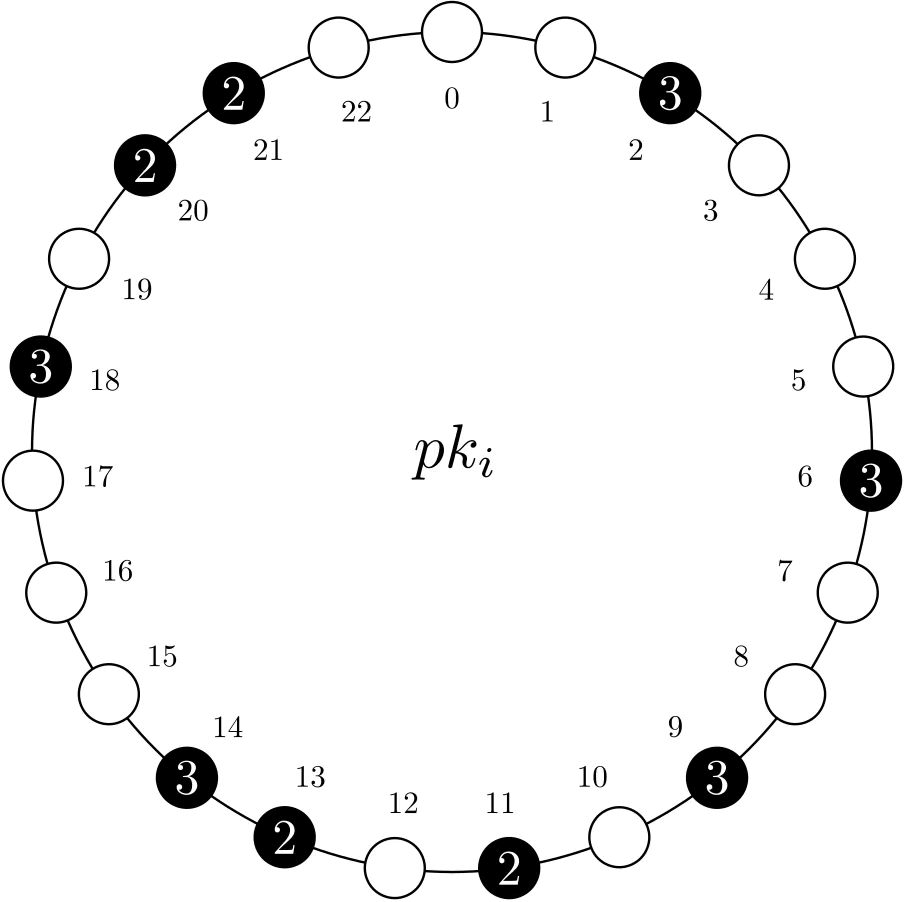
Choosing an optimal n depends on the current load. On one hand, a low number will lead to a high conflict probability under high loads. On the other, a large number increases storage and read overheads, and can be counterproductive for MRVs with low values. Therefore, MRVs employ a background worker that dynamically adjusts the number of records per MRV based on the workload, using, e.g., the MRV’s conflict rate.
In the example below, a higher load leads to an increased abort rate. To offset this, the adjust worker adds two new records, filling previously empty positions.
Figure 4. Example of the adjust worker adding two new records to MRV pki.
Balancing
Finally, skewed workloads can lead to imbalanced records. For example, in stock reservation use cases, we might have multiple small subtractions – clients buying the item – and a few large additions – the store restocking the item. This increases the conflict probability of subtract operations, reducing the usefulness of MRVs. Our solution is another background worker that periodically balances the amount between records, as exemplified in the animation below.
Figure 5. Example of the balance worker balancing amount among records in MRV pki.
Evaluation
MRVs are evaluated with experiments on different database management systems, including distributed systems where other solutions are not applicable. Namely, implementations of MRVs have been tested on: a centralized SQL system with PostgreSQL, often used in cloud-based managed services; a single-writer NoSQL data store with MongoDB; a multi-writer SQL database with MySQL Group Replication; and a cloud-native, multi-writer NewSQL system that we call System X.
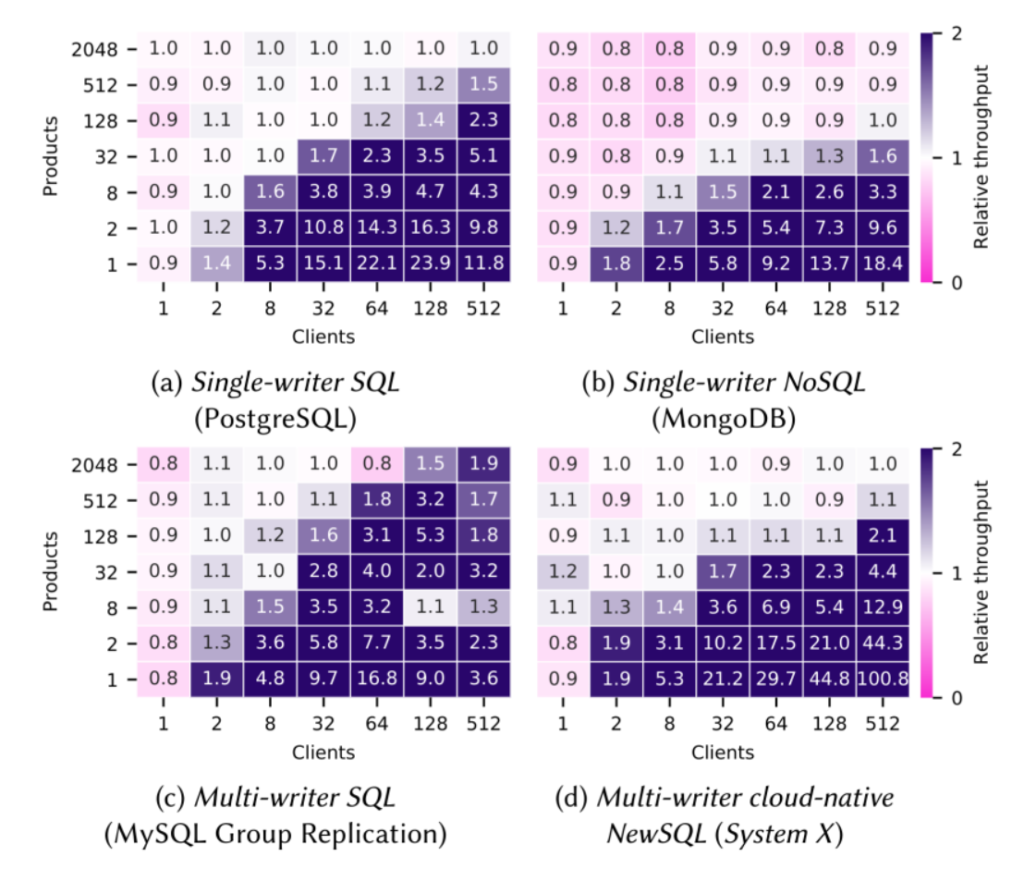
This test mimics a shopping application that keeps stocks of products. We increase contention both by increasing the number of concurrent clients (X-axis) as well as decreasing the number of products (Y-axis). The heatmaps below display the scale-up in throughput against the native single-record solution. These experiments show that the MRVs technique is widely feasible and advantageous in a spectrum of different database management systems, including NoSQL and distributed systems where an improvement of 100x can be observed in cases of extreme contention.
Figure 5. Performance comparison between MRVs and the native single-record I a variety of database systems.
Final Remarks
Multi-Record Values improve the performance of applications affected by the problem of numeric hotspots, by reducing the collision probability. The background workers ensure that MRVs adapt based on the current load, meaning write performance is improved while optimizing to reduce read and storage overheads.
The open challenge that remains is the feasibility of randomized splitting to data structures other than numeric values.
Nuno Faria and José Pereira. 2023. MRVs: Enforcing Numeric Invariants in Parallel Updates to Hotspots with Randomized Splitting. Proc. ACM Manag. Data 1, 1, Article 43 (May 2023). https://doi.org/10.1145/3588723